
SPSS 반복측정 분산분석 (Repeated measures ANOVA)
목차
1. 반복측정 분산분석
2. 분석방법
- 대비
- 사후검정
3. 결과해석
반복측정 분산분석 (Repeated measures ANOVA)
※ 3개 이상의 집단 간의 전후 차이를 비교하는 경우 OR 1개 이상의 집단이 3회 이상 측정을 한 경우
e.g.1) 실험군 1(PNF)과 실험군 2(스트레칭), 대조군(중재 X) 3개 그룹의 각 중재 전후 엉덩관절 굽힘 관절가동범위 변화에 대한 그룹별 및 전후 비교
e.g.1) 실험군 1(PNF)과 대조군(중재 X) 2개 그룹의 중재 전후 및 중재 후 1개월 후 엉덩관절 굽힘 관절가동범위 변화에 대한 그룹별 및 측정 시기별 비교
- 독립변수 : 운동 유형 (PNF & 스트레칭 & 중재 X)
- 종속변수 : 엉덩관절 굽힘 관절가동범위
기본조건
- 변수
- 독립변수(개체 간 요인: 그룹): 질적변수 (명목척도, 순서척도)
- 종속변수(개체 내 요인: 측정시기): 양적변수 (비척도, 등간척도)
1. 그룹별 비교 시
- 각 집단이 서로 독립적이어야 한다.
- 각 집단이 모두 정규분포여야 한다.
- 각 집단의 분산이 모두 동일해야 한다.
2. 시기별 비교 시
- 각 시기별 측정값 모두 정규분포여야 한다.
- 각 시기별 측정값의 분산이 모두 동일해야 한다.
가설검증
예시 1)
- 영가설 : 3개 그룹 간 비교 및 중재 전후 비교에서 어떠한 차이도 없다 (p > 0.05).
- 대립가설 : 3개 그룹 간 비교 및 중재 전후 비교에서 최소 1개 이상의 차이가 있다 (p ≤ 0.05).
예시 2)
- 영가설 : 그룹 간 비교 및 측정 시기별 비교에서 어떠한 차이도 없다 (p > 0.05).
- 대립가설 : 그룹 간 비교 및 측정 시기별 비교에서 최소 1개 이상의 차이가 있다 (p ≤ 0.05).
분석방법
1. 검정위치
분석 -> 일반선형모형 -> 반복측도

2. 검정 설정
'개체-내 요인이름'에 측정시기 등 반복된 요인의 이름 입력 -> '수준 수'에 측정 횟수 등 반복된 횟수 입력 -> '추가' 클릭 -> '정의' 클릭

'개체-내 변수'에 종속변수 추가 -> '개체-간 변수'에 독립변수 추가 -> '대비' 클릭

3. 대비
'요인'의 측정시기를 '다항'으로 유지 -> 그룹을 '단순'으로 변경 (참조범주는 대조군에 맞춰서 설정) -> 계속

- 편차(Deviation):
- 각 수준의 평균을 참조 범주를 제외한 모든 수준의 평균과 비교한다.
- 편차 대비는 모든 수준을 기준으로 하나의 참조 수준과의 차이를 검토한다.
e.g) 같은 근육군에 영향을 미치는 3가지의 운동 방법을 적용했을 때 각 운동 방법의 평균이 3가지 운동의 전반적인 평균과 얼마나 차이가 있는지 확인할 수 있다. - 단순(Simple): 그룹에 주로 사용한다 (측정시기의 중재 전 값을 참조범주로 해서 사용하기도 함).
- 서로 다른 각 수준의 평균을 지정된 수준의 평균과 비교한다.
- 주로 대조군이 있는 경우 사용하며, 대조군을 참조범주로 설정한다.
- 참조범주에서는 첫 번째 또는 마지막 집단을 선택할 수 있다.
e.g) 서로 다른 3개의 운동의 평균을 대조군의 평균과 비교한다. - 차이(Difference):
- 각 수준의 평균을 이전 수준의 평균과 비교한다.
- 이것은 일종의 순차적인 비교를 수행하는 방법이다.
e.g) 처음에는 기존의 운동을 적용하고 그 후 새로운 운동을 적용했을 때, 새로운 운동의 평균을 기존 운동의 평균과 비교한다. - Helmert:
- 요인의 각 수준의 평균을 후속 수준의 평균과 비교한다.
- 이 방법은 비교를 진행하는 각 단계마다 이전 단계의 수준을 제외하는 방식으로 작동한다 - 반복(Repeat):
- 각 수준의 평균을 후속 수준의 평균과 비교한다.
- Helmert와 유사하지만, 마지막 수준도 비교에 포함된다. - 다항(Polynomial): 측정시기 등에 주로 사용
- 다항 효과(선형, 2차, 3차 등)를 비교합니다.
- 선형 효과부터 시작하여 차수가 증가할수록 그 차수의 효과를 검토합니다.
- 이 방법은 데이터에서 추세를 파악하는 데 사용됩니다.
e.g) 시간이 지남에 따른 운동의 효과를 비교한다.
4. 사후검정 (그룹별 비교가 있는 경우)
'사후검정변수'에 개체-간-요인 추가 -> 사후검정 방법 선택 -> '계속'

용어 정리
- 검정력 : 검정력이 높을수록 실제로 발생한 차이를 더 잘 감지할 수 있다.
- 보수적인 검정방법 : 제1종 오류를 최소화하는 것이다.
- 제1종 오류 : 실제로는 차이가 없지만, 차이가 있다고 연구 결과가 나오는 오류이다.
- 검정 방법이 보수적일수록 통계적으로 유의미한 결괏값이 나올 확률이 줄어든다. - 검정력과 보수적인 검정방법은 대체로 반비례한다.
- 검정 방법이 보수적일수록 검정력이 낮다.
검정 방법
등분산이 가정된 경우
- Bonferroni : T 검정을 사용하며, t검정 반복시행으로 인한 1종 오류의 증가를 보정한 형태이다.
- n수 : 동일하지 않아도 된다.
- 특징 : 오류의 보정으로 인해 보수적으로 작용될 수 있다.
- 단점 : 그룹의 수가 많아질수록 검정력이 약해진다. - Tukey 방법 (Tukey's Honestly Significant Difference; HSD): F분포를 사용한다.
- n수 : 각 집단이 모두 동일해야 한다.
- 특징 : n수가 같은 경우 많이 선호된다.
- 단점 : 표본 수가 적을수록 검정력이 약해진다. - Scheffe : F분포를 사용한다.
- n수 : 동일하지 않아도 된다.
- 특징 : 표본이 클수록 검정력이 증가한다.
- 단점 : 큰 차이가 있어야 유의한 차이로 인정하는 매우 보수적인 방법이다. - Duncan : F분포를 사용한다.
- n수 : 각 집단이 모두 동일해야 한다.
- 특징 : 작은 차이를 구분해야 하는 경우에 선호된다.
- 단점 : 제1종 오류가 발생할 확률이 높다.
등분산이 가정되지 않은 경우
- Dunnett의 T3
- 표준화 최대 계수를 기준으로 하는 쌍대 비교 검정을 수행합니다.
- n수가 다른 경우 검정력이 더 높다.
- 제1형 오류의 통제가 강하다. - Games-Howell
- 경우에 따라 자유롭게 수행되는 쌍대 비교 검정입니다.
- n수가 다른 경우 사용가능
- 보편적으로 선호된다.
4. 선택사항
- '도표'에서 개체-간-요인을 '선구분 변수'에 추가 -> 개체-내-요인을 '수평축 변수'에 추가 -> '추가' 클릭 -> 계속
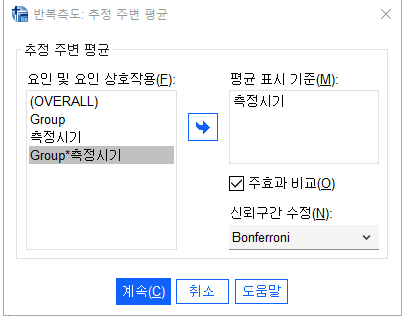
- '평균 표시 기준'에서 개체-내-요인을 추가 -> '주효과 비교' 클릭 -> '신뢰구간 수정'을 사후검정 방법에 맞춰서 설정 -> 계속
- '옵션'에서 기술통계량 & 동질성 검정 체크 -> 계속 -> 확인

결과해석
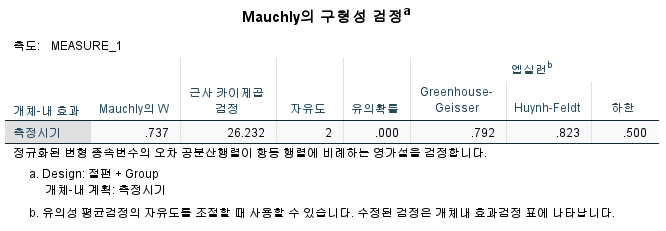
Mauchly의 구형성 검정
- 유의확률(p) ≥ 0.05 : 영가설(서로 차이가 없음) 채택으로 구형성을 가정한다.
- 유의확률(p) < 0.05 : 구형성을 가정하지 않는다.
- p값이 0.05 이상이기 때문에 '등분산을 가정함'에 대한 사후검정 결괏값을 확인한다.
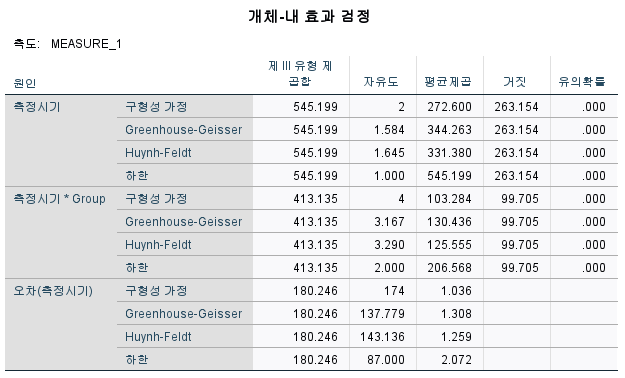
- 구형성 가정 여부에 따른 결과 확인
- 구형성 가정 시 : '구형성 가정' 결괏값을 확인한다.
- 구형성 가정 미충족 시 :
- 앱실론 값이 0.75 미만인 경우 : Greenhouse-Geisser 값을 확인한다.
- 앱실론 값이 0.75 이상인 경우 : Huynh-Feldt 값을 확인한다.
e.g) 앱실론 값이 0.792 및 0.823으로 Huynh-Feldt 값을 확인한다. - 개체-내 효과 검정에 대한 p값
'유의확률' = p값
1) 측정시기
- p ≤ 0.05 : 측정시기 간에 1개 이상의 유의미한 차이가 있다.
- p > 0.05 : 측정시기 간에 유의미한 차이가 없다.
2) 측정시기*Group
- p ≤ 0.05 : 그룹별 및 측정시기 간에 1개 이상의 유의미한 차이가 있다.
- p > 0.05 : 그룹별 및 측정시기 간에 유의미한 차이가 없다.
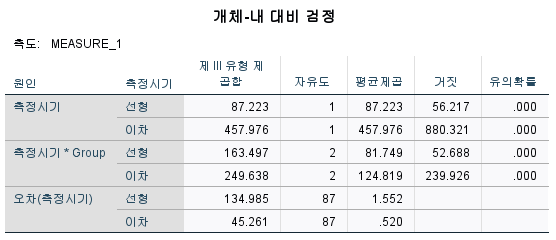
- 개체-내 대비 결괏값 확인
- '선형' 및 '이차'에 대한 p값을 통해 몇 차식 다항식 회귀가 적합한지 확인할 수 있다.
선형(p ≤ 0.05) & 이차(p ≤ 0.05) -> 이차 형식 관계
선형(p ≤ 0.05) & 이차(p > 0.05) -> 선형 형식 관계
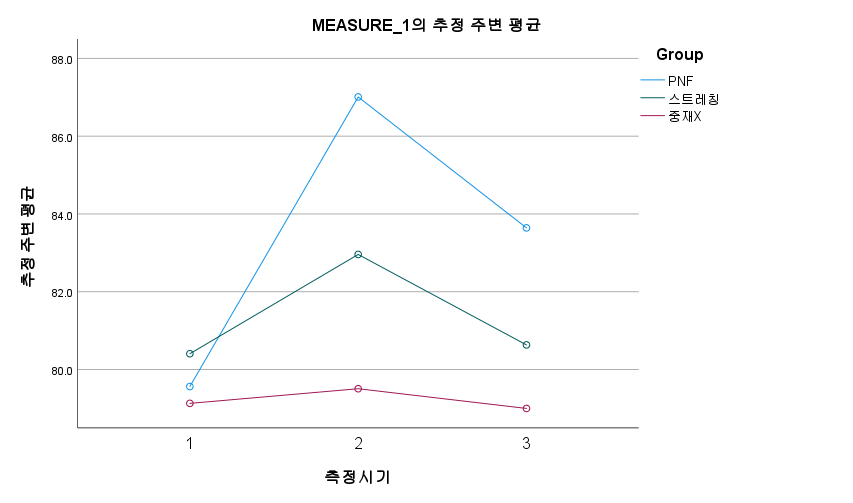
선형(p > 0.05) & 이차(p > 0.05) -> 유의미한 차이가 없다. - 교호작용 확인 (측정시기 * Group)
※ 2개 이상의 요인이 서로 영향을 미쳐, 결과적으로 결괏값에 영향을 미쳤는지 확인하는 것이다.
- 교호작용이 유의미한 경우 각 요인 별로 따로 분석하는 것이 좋다.
e.g) 측정시기와 그룹 간에 교호작용이 있는 경우 그룹 간 ANOVA와 각 그룹별로 반복측정 ANOVA를 따로 시행해 보는 것이 좋다.
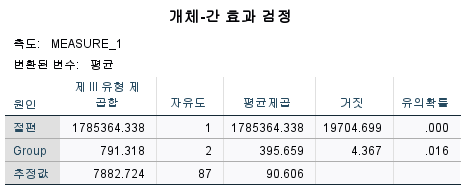
- 개체-간 효과 검정에 대한 p값
'유의확률' = p값
- p ≤ 0.05 : 그룹 간에 1개 이상의 유의미한 차이가 있다.
- p > 0.05 : 그룹 간에 유의미한 차이가 없다.
e.g) p=0.016으로 그룹 간 유의미한 차이가 있다.
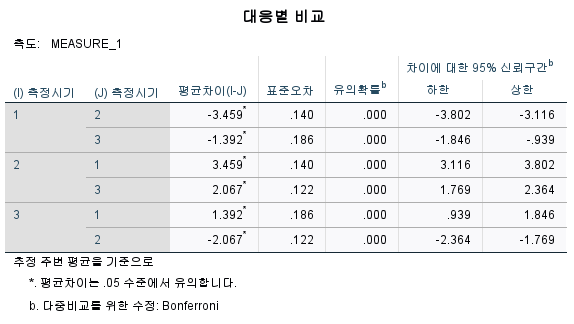
- 개체-내 효과 검정에 대한 세부적인 비교값
'유의확률' = p값
- p ≤ 0.05 : 특정 측정시기 간에 유의미한 차이가 있다.
- p > 0.05 : 특정 측정시기 간에 유의미한 차이가 없다.
e.g) p=0.000으로 측정 1 및 측정 2 간에 유의미한 차이가 있다.
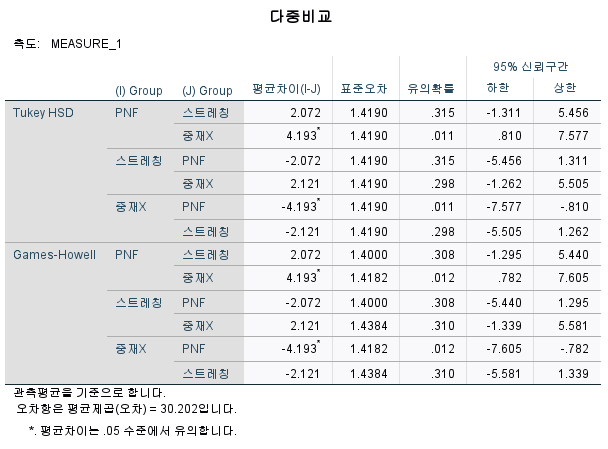
- 개체-간 효과 검정에 대한 사후검정
'유의확률' = p값
- p ≤ 0.05 : 특정 그룹 간에 유의미한 차이가 있다.
- p > 0.05 : 특정 그룹 간에 유의미한 차이가 없다.
e.g) p=0.011로 PNF 그룹과 및 중재 X 그룹 간에 유의미한 차이가 있다.
또한 평균차이 값이 양수(+)이므로, PNF 그룹의 값이 중재 X 그룹의 값보다 크다.
첨부파일
관련 참고자료
IBM SPSS 반복 측도:대비
https://www.ibm.com/docs/ko/spss-statistics/beta?topic=contrasts-define-contrast
관련 글
2024.03.18 - [SPSS] - SPSS 일원배치 분산분석 방법 및 해석 / One-way Analysis of Variance
2024.03.18 - [SPSS] - SPSS 분산분석 사후검정 종류 및 특징 / Post-hoc (one-way ANOVA)