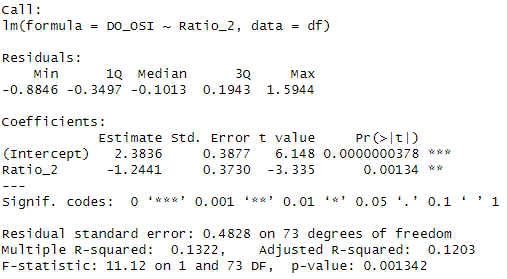
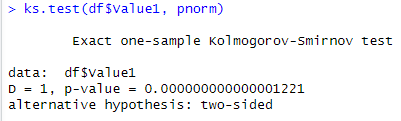
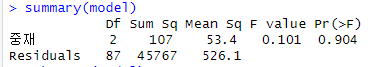R STUDIO 이원배치 분산분석 / Two-way Analysis of Variance (two way ANOVA)이원배치 분산분석 (Two-way ANOVA)※ 2개 이상의 독립변수가 종속변수에 미치는 영향(평균비교) 및 독립변수 간의 상호작용 확인 e.g.) 2개의 독립변수 및 1개의 종속변수 - 독립변수1 : 성별 (남 & 여) - 독립변수2 : 운동 유형 (PNF & 스트레칭 & 중재 X) - 종속변수 : 엉덩관절 굽힘 관절가동범위기본조건변수- 독립변수: 질적변수 (명목척도, 순서척도)- 종속변수: 양적변수 (비척도, 등간척도)독립변수 내 모든 집단이 서로 독립적이어야 한다.독립변수로 만들어지는 각 조합은 모두 정규분포여야 한다. 독립변수로 만들어지는 각 조합의 분산이 모두 동..