
R STUDIO 상관분석 / Correlation Analysis
(Pearson correlation & Spearman's rank correlation )
목차
1. 상관분석
2. 피어슨 상관분석
3. 스피어맨 상관분석[비모수]
4. 상관행렬
1. 상관분석 (Correlation analysis)
※ 2개 변수 간의 관련성을 확인하는 것이다.
- 상관관계만 확인이 가능하며 인과관계는 회귀분석을 통해 확인할 수 있다.
e.g.) 넙다리네갈래근의 근긴장도와 엉덩관절의 폄 근력의 상관관계를 분석한다.
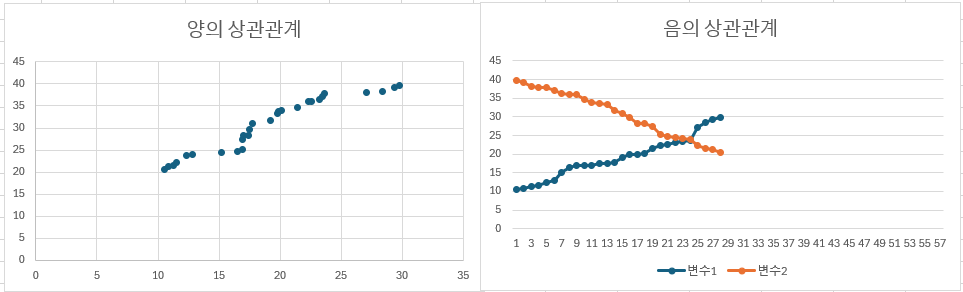
상관관계
- 상관관계는 왼쪽의 산포도 또는 오른쪽의 선형 그래프 등으로 표현할 수 있다.
양(+)의 상관관계 : 변수 1이 증가할 때 변수 2가 함께 증가한다.
음(-)의 상관관계 : 변수 1이 증가할 때 변수 2는 감소한다.
- 상관계수를 사용할 수 없는 경우
- 직선형이 아닌 곡선형 관계가 있는 경우
- 극단값(이상값)이 있는 경우
- 산포도에서 2개 이상의 소집단 분포가 보이는 경우

상관계수에 따른 상관정도
※ 연구 결과에 따라 상관계수에 대한 기준이 다르며, 대체로 0.8 이상부터 괜찮은 상관관계라고 분류한다.
- Meyers & Blesh, 1962
- |0.90~0.99| : 높은 상관관계
- |0.80~0.89| : 양호한 상관관계
- |0.70~0.79| : 보통의 상관관계
- |0.00~0.69| : 낮은 상관관계 - Schober, Boer, & Schwarte, 2018
- |0.90~1.00| : 매우 높은 상관관계
- |0.70~0.89| : 높은 상관관계
- |0.40~0.69| : 중간 정도의 상관관계
- |0.10~0.39| : 낮은 상관관계
- |0.00~0.09| : 매우 낮은 상관관계
상관관계와 신뢰도(Reliability)의 차이
- 상관관계는 즉 변수 1이 증가할 때 변수 2가 같이 증가하거나 반대로 감소하는 '경향'에 대한 것이다.
- 신뢰도는 2번 이상 측정 시 경향이 아닌 동일한 값이 나오는 '일관성'에 대한 것이다.

2. 피어슨 상관분석 (Pearson Correlation)
기본조건
- 변수 : 양적변수 (비척도, 등간척도)
- 모든 변수가 정규분포여야 한다.
가설검증
- 귀무가설 : 넙다리네갈래근의 근긴장도와 엉덩관절의 폄 근력은 상관관계가 없다 (p > 0.05).
- 대립가설 : 넙다리네갈래근의 근긴장도와 엉덩관절의 폄 근력은 상관관계가 있다 (p ≤ 0.05).
Code :
cor.test(Dataset$종속변수1, Dataset$종속변수2)
- cor.test() : 2개의 변수 데이터의 상관관계를 분석한다.
- Dataset$종속변수1 : Dataset에서 종속변수1에 해당하는 변수 데이터를 추출한다.
결과 해석

- p값(p-value)
- p > 0.05 : 2개 변수에 유의미한 상관관계가 없다.
- p ≤ 0.05 : 2개 변수에 유의미한 상관관계가 있다.
- 95% 신뢰구간 (Confidence Interval)
모집단이 실제로 포함될 것으로 예측되는 범위이다.
- 하한 or 상한 = 0 : p = 0.05
- 하한 & 상한 = 마이너스(-) 값 OR 플러스(+) 값 : p < 0.05
- 하한 < 0 < 상한 : p > 0.05 - 상관계수(sample estimates : cor)
- 상단의 '상관계수에 따른 상관정도' 내용 참고
3. [비모수] 스피어맨 상관분석 (Spearman's rank Correlation)
※ 피어슨 상관분석에 대응하는 비모수 검정이다.
- 변수 중 1개 이상이 순서척도인 경우
e.g.) 상중하 - 변수 중 1개 이상이 정규분포를 이루지는 못한 경우
- 표본크기가 작은 경우
가설검증
- 귀무가설 : 교육 수준(초, 중, 고, 대학, 대학원)과 건강 관련 삶의 질은 상관관계가 없다 (p > 0.05).
- 대립가설 : 교육 수준(초, 중, 고, 대학, 대학원)과 건강 관련 삶의 질은 상관관계가 있다 (p ≤ 0.05).
Code :
cor.test(Dataset$종속변수1, Dataset$종속변수2, method = 'spearman')
- cor.test() : 2개의 변수 데이터의 상관관계를 분석한다.
- Dataset$종속변수1 : Dataset에서 종속변수1에 해당하는 변수 데이터를 추출한다.
- method : spearman -> 스피어맨 상관분석으로 지정한다.
결과 해석

- p값(p-value)
- p > 0.05 : 2개 변수에 유의미한 상관관계가 없다.
- p ≤ 0.05 : 2개 변수에 유의미한 상관관계가 있다.
- 95% 신뢰구간 (Confidence Interval)
모집단이 실제로 포함될 것으로 예측되는 범위이다.
- 하한 or 상한 = 0 : p = 0.05
- 하한 & 상한 = 마이너스(-) 값 OR 플러스(+) 값 : p < 0.05
- 하한 < 0 < 상한 : p > 0.05 - 상관계수(sample estimates : rho)
- 상단의 '상관계수에 따른 상관정도' 내용 참고
4. 상관행렬
※ 3개 이상의 종속변수에 대해서 동시에 상관분석을 시행 및 결과를 표로 나타내는 방법이다.
Code :
수정된 Dataset <- select(Dataset, 시작 변수:종료 변수)
corr.test(수정된 Dataset, use = "complete", method = "pearson", adjust = "none")
- select() : Dataset에서 분석에 사용할 변수의 시작지점과 종료지점을 설정해서 새로운 Dataset을 만든다.
- corr.test() : 수정된 Dataset에 있는 모든 변수 데이터의 각 상관관계를 분석한다.
- use : complete -> 결측값이 있는 관측치를 제거하는 것
- method : pearson -> 피어슨 상관분석으로 지정 / spearman -> 스피어맨 상관분석으로 지정
- adjust : none -> p값에 대한 보정을 적용하지 않는다.
결과 해석

- 상관계수(correlation matrix)
- 상단의 '상관계수에 따른 상관정도' 내용 참고
- p값(probability values)
- p > 0.05 : 2개 변수에 유의미한 상관관계가 없다.
- p ≤ 0.05 : 2개 변수에 유의미한 상관관계가 있다.
2024.05.10 - [R] - R studio에서 Excel 파일 불러오기
2024.05.11 - [R] - R STUDIO TIP 옵션 (scipen, digits, max.print)
2024.05.12 - [R] - R STUDIO 상자도표(Box plot) / ggsignif(ggplot2, ggsignif)
2024.05.13 - [R] - R STUDIO 그룹 분할 및 변수 설정 / dplyr
2024.05.15 - [R] - R STUDIO 정규성 검정 (Kolmogorov-Smirnov test & Shapiro-Wilk test)
2024.05.21 - [R] - R STUDIO 단순선형회귀분석 (Simple Linear Regression)
2024.05.23 - [R] - R STUDIO 다중선형회귀분석 (Multiple Linear Regression)
2024.05.25 - [R] - R STUDIO 등분산 검정 (Levene 검정 & Bartlett 검정 & F 검정)
2024.05.26 - [R] - R STUDIO 독립 표본 t 검정 (Independent t test)
2024.06.02 - [R] - R STUDIO 대응 표본 t 검정 (Paired-Samples T Test)
'R' 카테고리의 다른 글
| R STUDIO 신뢰도 분석 / 급내상관계수 (Intraclass Correlation Coefficient; ICC) (1) | 2024.06.09 |
|---|---|
| R STUDIO 일원배치 분산분석 / One-way Analysis of Variance (one way ANOVA) (0) | 2024.06.04 |
| R STUDIO 대응 표본 t 검정 (Paired-Samples T Test) (0) | 2024.06.02 |
| R STUDIO 독립 표본 t 검정 (Independent t test) (0) | 2024.05.26 |
| R STUDIO 등분산 검정 (Levene 검정 & Bartlett 검정 & F 검정) (0) | 2024.05.25 |